Resumo do Google I/O 2024: Projeto Astra, Veo, Gemini turbinado, Busca com IA
Conferência anual para desenvolvedores do Google foi focada em inteligência artificial e apresentou diversas novas ferramentas

Atualizado em
O Google deu início à sua conferência anual para desenvolvedores, a Google I/O, nesta terça-feira (14). Assim como na edição do ano passado, as novidades do evento giraram em torno de dois temas principais: inteligência artificial (IA) e ferramentas de produtividade. Diferente de 2023, a empresa deixou a timidez de lado e mostrou que mergulhou de cabeça na IA.
O Gemini, grande modelo de linguagem (LLM) do Google, foi o grande destaque do evento. A versão mobile, Gemini Nano, agora com recursos multimodais, permite extrair informações de diversos formatos, como texto, fotos, áudio, web, vídeos de redes sociais e vídeos ao vivo da câmera do smartphone, e sintetizar essas informações para resumir o conteúdo ou responder a perguntas relacionadas.
A IA Gemini também está sendo integrada à suíte de ferramentas de escritório Workplace do Google. A partir de hoje, um botão para ativar o Gemini aparecerá no painel lateral de diversos aplicativos do Google, incluindo Gmail, Google Drive, Docs, Sheets e Slides. O assistente Gemini pode responder a perguntas, auxiliar na redação de e-mails ou documentos, ou fornecer resumos de documentos longos ou conversas por e-mail.
Um novo recurso chamado “Gems” permite definir rotinas automatizadas para tarefas que você deseja que o Gemini realize regularmente – bem ao estilo dos GPTs, os “plugins” do ChatGPT. Você pode configurá-los para gerenciar diversas tarefas digitais e executá-las com um comando de voz ou um prompt de texto.
Novos modelos Gemini
Dois novos modelos de IA Gemini foram apresentados, focados em diferentes tipos de tarefas:
- Gemini 1.5 Flash: Mais rápido e com menor latência, otimizado para tarefas que exigem rapidez.
- Gemini 1.5 Pro: Versão em nuvem mais robusta, disponível para todos os desenvolvedores.
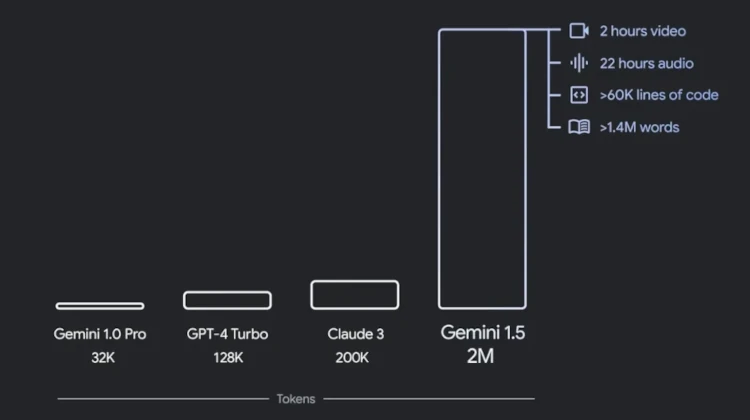
O Gemini 1.5 Pro, já havia sido lançado em fevereiro. Apesar de manter a mesma numeração, a nova versão traz uma melhoria significativa: uma janela de contexto de 2 milhões de tokens.
O tokens são pedaços de dados usados pelos modelos de linguagem para processar informações. A janela de contexto, por sua vez, determina a quantidade máxima de tokens que o modelo consegue processar simultaneamente. O Gemini 1.5 Pro poderá trabalhar com um volume muito maior de documentos ou sequências longas de vídeos codificados. A título de comparação, a versão anterior do modelo tinha limite de 1 milhão de tokens, e o GPT-4 Turbo da OpenAI fica em 128.000 tokens.
Para tornar a tecnologia mais acessível, a gigante das buscas também revelou o Gemini 1.5 Flash. Apresentado como uma versão leve, mais rápida e econômica do 1.5 Pro, o Flash é ideal para tarefas frequentes e em grande volume.
O Gemini 1.5 Pro, a versão em nuvem mais robusta do Gemini, já está disponível para todos os desenvolvedores com uma assinatura Gemini Advanced.
Projeto Astra e vídeos
O Projeto Astra é um chatbot visual, uma versão aprimorada do Google Lens. Ele permite aos usuários abrirem as câmeras de seus telefones e fazerem perguntas sobre praticamente qualquer coisa ao seu redor, apontando a câmera para objetos. O vídeo abaixo mostra como você pode interagir com o que o Astra está vendo usando sua voz para fazer perguntas – exatamente como o GPT-4o, anunciado pela OpenAI ontem.
Ainda em fase inicial e sem planos de lançamento definidos, o Projeto Astra da Google sinaliza avanços significativos para a integração de suas funcionalidades em produtos como o aplicativo Gemini ainda este ano, na funcionalidade denominada “Gemini Live”.
O Google Labs, divisão experimental da empresa, apresentou um conjunto de ferramentas de IA para fins criativos:
- VideoFX: Gera vídeos em 1080p com base em prompts de texto, oferecendo mais flexibilidade na produção de vídeos.
- ImageFX: Gera imagens de alta resolução com menos artefatos digitais e melhor análise de prompts de usuários.
- Modo DJ no MusicFX: Gera loops e amostras de música com base em prompts, permitindo que músicos criem músicas de forma inovadora.
Veo
O Google também revelou um novo modelo de IA generativa para vídeos chamado Veo, criado por seus pesquisadores da renomada divisão DeepMind, usando o VideoFX. De acordo com uma postagem do Google DeepMind no Twitter, o Veo é capaz de criar “clipes de alta qualidade em 1080p que podem ultrapassar 60 segundos”. O texto diz ainda que “do realismo fotográfico ao surrealismo e animação, ele pode lidar com uma variedade de estilos cinematográficos”.
O objetivo do Veo, segundo o Google, é “ajudar a criar ferramentas que tornem a produção de vídeo acessível a todos”. O modelo suporta transformações de texto para vídeo, vídeo para vídeo e imagem para vídeo.
Apesar de ser um grande avanço, o Veo ainda não parecer ser tão bom quanto o Sora, da Open AI. Ainda precisa maturar mais.
Pesquisas com AI e Google Fotos
As novas capacidades de IA do Google representam uma mudança significativa para seu produto principal, a o serviço de buscas. Algumas das novidades incluem:
- Pesquisa organizada por IA: Resultados de pesquisa mais precisos e legíveis, além da capacidade de obter respostas melhores para consultas mais longas e pesquisas com fotos.
- Visões gerais de IA: Resumos breves que reúnem informações de várias fontes para responder à pergunta inserida na caixa de pesquisa.
- Raciocínio Multifásico: Permite encontrar várias camadas de informações sobre um tópico, facilitando a pesquisa aprofundada, como no planejamento de viagens.
O Google Fotos recebeu ferramentas robustas de pesquisa visual. Com o novo recurso “Pergunte ao Fotos”, os usuários podem utilizar o Gemini para pesquisar suas fotos e obter resultados mais granulares do que antes. Como exemplo, agora você pode informar o número da placa do seu carro para que o Gemini utilize pistas contextuais para encontrá-lo em todas as suas fotos.
O Google garante que a ferramente não coleta dados sobre as fotos dos usuários para treinar outros modelos de IA Gemini – apena o do próprio Google Fotos. O recurso estará disponível em breve.
Segurança e Privacidade
O Google também apresentou novidades em segurança e privacidade. Com o Gemini, o Android detecta linguagem enganosa em chamadas telefônicas, interrompendo-as e alertando o usuário. O recurso funciona localmente no dispositivo, sem enviar as chamadas para a nuvem.
Para combater desinformação, deepfakes e spam de phishing, foi criada uma ferramenta de marca d’água para distinguir mídias criadas com IA. O SynthID será lançado como ferramenta de código aberto em meados de 2024.